¿Sabes cuál es el modelo de almacenamiento ideal para optimizar tu arquitectura software? Explora esta guía sencilla y práctica sobre los modelos de almacenamiento más populares: en filas, en columnas, de documentos y clave-valor. Descubre las ventajas de cada uno, en qué casos utilizarlos y cómo aplicarlos en la nube con ejemplos de AWS. ¡Dale a tus aplicaciones el rendimiento que necesitan y aprende a elegir la estructura perfecta para almacenar y acceder a tus datos!
Comparativo De los modelos de almacenamiento
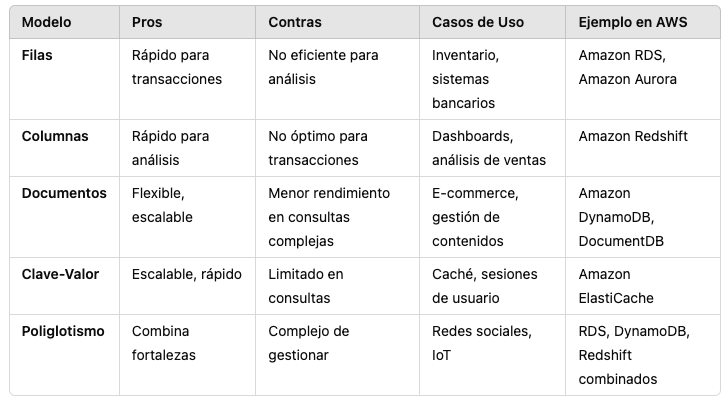
Almacenamiento en Filas: El Modelo de Base de Datos Ideal para Transacciones Rápidas
El almacenamiento en filas, o row-oriented storage, es un modelo de base de datos ampliamente utilizado en aplicaciones donde el acceso a registros completos es fundamental. En este modelo, cada registro (o fila) se almacena como una unidad en un mismo bloque de almacenamiento. Cada fila contiene todos los atributos de una entidad específica, lo cual hace que este tipo de almacenamiento sea eficiente para aplicaciones que requieren leer o escribir registros completos en una sola operación. Este modelo es común en bases de datos relacionales y es especialmente adecuado para sistemas de procesamiento de transacciones en línea (OLTP).
El principal beneficio del almacenamiento en filas es su capacidad para recuperar registros completos de manera rápida y eficiente. Este modelo es ideal para sistemas donde las aplicaciones necesitan acceder a todos los atributos de una entidad al mismo tiempo, como es el caso de un sistema de inventarios o una aplicación bancaria. Por ejemplo, en un sistema de gestión de inventarios, cada fila puede contener todos los detalles de un producto, como nombre, cantidad, precio y ubicación en almacén. Al mantener estos datos juntos en una misma fila, las consultas que necesitan acceder a todos estos atributos pueden ejecutarse de forma rápida y optimizada.
Sin embargo, este modelo presenta algunas limitaciones cuando se trata de análisis de datos o de cargas de trabajo de tipo OLAP, donde los usuarios suelen acceder a pocos atributos de una gran cantidad de registros. Como el modelo de almacenamiento en filas siempre recupera todos los datos de una fila, no es eficiente para consultas analíticas que solo necesitan algunos atributos específicos. Esto significa que, en aplicaciones donde el objetivo es analizar patrones o tendencias a partir de grandes volúmenes de datos, el almacenamiento en columnas puede ser una mejor opción, ya que permite un acceso más selectivo a los datos y una mejor compresión.
Otra limitación del almacenamiento en filas es la escalabilidad, ya que a medida que el volumen de datos crece, puede ser más difícil de gestionar. La estructura rígida de las bases de datos relacionales orientadas a filas no siempre permite un crecimiento eficiente en aplicaciones que requieren expansión rápida y acceso a datos complejos. Por ello, este modelo puede no ser el mejor para sistemas que necesitan escalar horizontalmente o para aquellos con datos menos estructurados y altamente variables.
Un ejemplo claro de la aplicación del almacenamiento en filas es en sistemas bancarios y financieros, donde se requiere que los datos de transacciones se almacenen de forma integral. En una base de datos en filas, cada transacción bancaria se registra como una fila con atributos como fecha, monto, número de cuenta y tipo de transacción, lo cual facilita el acceso rápido a los detalles completos de cada transacción. Servicios en la nube como Amazon RDS y Amazon Aurora de AWS aprovechan este modelo de almacenamiento para optimizar la eficiencia en aplicaciones de transacciones y garantizar la integridad de los datos en cada operación.
Almacenamiento en Columnas (Column-oriented Storage): Ideal para Análisis de Grandes Volúmenes de Datos
El almacenamiento en columnas o column-oriented storage es un modelo de base de datos que organiza los datos por columnas en lugar de filas, lo que lo convierte en una opción extremadamente eficiente para consultas analíticas. En este modelo, cada columna de datos se almacena de manera separada, lo que permite a las bases de datos almacenar solo los valores relevantes para las consultas. Este enfoque es particularmente útil para aplicaciones de procesamiento analítico en línea (OLAP), donde se necesita acceder rápidamente a grandes volúmenes de datos, pero solo se requieren algunos atributos de muchas filas.
Uno de los principales beneficios del almacenamiento en columnas es su capacidad para optimizar las consultas analíticas. En lugar de leer un registro completo, como en el almacenamiento en filas, el modelo basado en columnas permite que solo se lean los datos de las columnas relevantes para una consulta. Esto resulta en una mayor velocidad de procesamiento, especialmente en casos donde solo se necesitan pocos atributos de muchas filas. Por ejemplo, en un análisis de ventas, los analistas podrían estar interesados únicamente en las columnas de «total de ventas» y «región», y al almacenar los datos de forma columnar, pueden acceder rápidamente a esta información sin tener que leer todas las demás columnas relacionadas, como «producto» o «cliente».
Además de su eficiencia en las consultas, el almacenamiento en columnas también ofrece una mayor capacidad de compresión. Al almacenar valores similares en una misma columna, el sistema puede aplicar técnicas de compresión más eficientes, lo que reduce el tamaño de los datos y mejora el rendimiento general. Esto es especialmente valioso cuando se trabaja con grandes volúmenes de datos, ya que se reduce la cantidad de almacenamiento necesario y se acelera la lectura y escritura de datos.
No obstante, este modelo no está exento de desventajas. El almacenamiento en columnas no es óptimo para transacciones que requieren el acceso a registros completos. En sistemas OLTP, donde cada operación necesita acceder a todos los atributos de un registro, el modelo de almacenamiento en columnas puede resultar menos eficiente. Además, debido a su diseño, el almacenamiento en columnas puede ser más complejo de gestionar y mantener que el almacenamiento en filas, lo que requiere un enfoque más especializado.
El uso del almacenamiento en columnas es ideal en aplicaciones donde las consultas de agregación o análisis de grandes conjuntos de datos son esenciales. Por ejemplo, en un sistema de análisis de datos de marketing, donde se necesita realizar consultas sobre métricas como el gasto total de los clientes por región, el almacenamiento en columnas es extremadamente eficiente. Almacenar los datos de ventas por columnas (como «gasto», «región» y «fecha») permite que las consultas se realicen rápidamente, incluso con grandes volúmenes de datos.
Un ejemplo prominente de la implementación de almacenamiento en columnas es Amazon Redshift, un servicio de almacenamiento de datos completamente administrado y basado en columnas. Este servicio de AWS está diseñado específicamente para consultas analíticas rápidas y de alto rendimiento. Redshift utiliza el almacenamiento en columnas para optimizar las consultas y mejorar la eficiencia en el procesamiento de grandes volúmenes de datos, lo que lo convierte en una solución ideal para aplicaciones de business intelligence, análisis de datos y big data.
Almacenamiento de Documentos (Document Store): Flexibilidad para Datos No Estructurados
El almacenamiento de documentos o document store es un modelo de base de datos NoSQL que almacena datos en un formato de documento, típicamente en JSON, BSON o XML. Cada documento es una unidad de datos autocontenida que puede incluir una amplia variedad de tipos de información, como texto, números, fechas o incluso archivos binarios. Este modelo se diferencia de las bases de datos relacionales tradicionales al no requerir una estructura rígida de tablas y filas, lo que lo convierte en una opción ideal para aplicaciones que necesitan manejar datos semi-estructurados o no estructurados, como documentos de texto o registros de usuario.
La principal ventaja del almacenamiento de documentos es su flexibilidad. Dado que cada documento puede tener su propia estructura interna, no es necesario adherirse a un esquema predefinido como en las bases de datos relacionales. Esto significa que es más sencillo adaptar la base de datos a cambios en los requisitos de los datos sin tener que modificar todo el sistema. Esta característica hace que los almacenamientos de documentos sean ideales para aplicaciones que manejan tipos de datos diversos o que requieren una rápida evolución, como aplicaciones web, plataformas de gestión de contenido y sistemas de registro de usuarios.
El almacenamiento de documentos también es ideal para datos jerárquicos o anidados, lo que lo hace adecuado para representar objetos complejos. Por ejemplo, en una aplicación de gestión de clientes, un documento podría almacenar no solo los detalles del cliente (nombre, dirección, teléfono), sino también sus pedidos, interacciones pasadas y otros datos relacionados, todo dentro de un solo documento. Esto permite una representación más natural de los datos y facilita las consultas que deben acceder a toda la información relacionada con un solo elemento, sin necesidad de realizar múltiples joins o consultas complicadas.
No obstante, el almacenamiento de documentos tiene algunas limitaciones en comparación con los sistemas de bases de datos relacionales. Una de las principales desventajas es la falta de consistencia transaccional en muchas implementaciones de bases de datos de documentos. A diferencia de las bases de datos SQL, que garantizan una alta consistencia mediante el uso de transacciones, muchas bases de datos de documentos operan bajo un modelo de consistencia eventual, lo que significa que los cambios pueden no ser inmediatamente visibles en todas las réplicas de los datos. Esto puede ser un inconveniente para aplicaciones donde se requiere una alta consistencia en tiempo real.
Además, debido a la naturaleza flexible de los documentos, es posible que se presenten problemas de integridad de datos si no se tiene cuidado con la estructura de los documentos. Como no hay un esquema predefinido, es más difícil garantizar que los datos sean consistentes o que se sigan las reglas de negocio adecuadas, lo que puede llevar a errores o dificultades en el mantenimiento de los datos a largo plazo.
El almacenamiento de documentos es particularmente útil en casos donde los datos no siguen una estructura rígida y pueden variar ampliamente entre registros. Por ejemplo, en sistemas de gestión de contenido, donde los documentos de texto pueden contener diferentes tipos de información (imágenes, videos, texto sin formato, metadatos), un modelo de almacenamiento de documentos permite almacenar todos estos datos dentro de un único documento, lo que facilita el acceso y la gestión de la información de manera eficiente.
MongoDB, uno de los sistemas de bases de datos NoSQL más populares, es un ejemplo destacado de un almacenamiento de documentos. MongoDB permite almacenar y consultar grandes cantidades de datos en formato JSON, lo que lo hace ideal para aplicaciones modernas que manejan datos semi-estructurados o que evolucionan rápidamente. Amazon DocumentDB es un servicio administrado que ofrece compatibilidad con MongoDB y es ideal para aplicaciones que necesitan almacenar y consultar grandes volúmenes de documentos de manera escalable y eficiente.
En resumen, el almacenamiento de documentos es una opción ideal para aplicaciones que manejan datos semi-estructurados o no estructurados, donde la flexibilidad, escalabilidad y la representación jerárquica de los datos son prioritarias. Sin embargo, su uso requiere un enfoque cuidadoso en cuanto a la consistencia de los datos y la gestión de la integridad, para evitar problemas a medida que la base de datos crece.
Almacenamiento de Clave-Valor (Key-Value Store): Simplicidad y Alta Velocidad para Datos No Relacionales
El almacenamiento de clave-valor o key-value store es uno de los modelos más simples y rápidos de bases de datos NoSQL. En este modelo, los datos se almacenan como pares de clave y valor, donde la clave es un identificador único y el valor es la información asociada. La clave actúa como un índice, lo que permite acceder a los valores de manera extremadamente rápida. Este modelo es ampliamente utilizado en aplicaciones que requieren una alta velocidad de acceso y escalabilidad, especialmente cuando la estructura de los datos es sencilla y no se necesita realizar consultas complejas.
La principal ventaja del almacenamiento de clave-valor es su simplicidad y alto rendimiento. Al no requerir una estructura compleja como las bases de datos relacionales, el acceso a los datos es muy eficiente. Los sistemas de almacenamiento de clave-valor pueden manejar millones de operaciones de lectura y escritura por segundo, lo que los hace ideales para aplicaciones de alto rendimiento, como sistemas de caching o almacenamiento de sesiones de usuario. En estas aplicaciones, cada usuario puede tener un valor asociado a su ID de sesión, y la clave se utiliza para acceder rápidamente a esa información.
Otra gran ventaja de los almacenes de clave-valor es que son altamente escalables. Dado que las claves son únicas y el sistema no requiere relaciones complejas entre los datos, se pueden distribuir fácilmente en múltiples servidores o nodos, permitiendo una expansión horizontal sin comprometer el rendimiento. Esto es particularmente valioso en aplicaciones que necesitan escalar de manera rápida y eficiente, como en plataformas de comercio electrónico, donde se manejan miles de transacciones por segundo y los datos de los usuarios deben estar disponibles instantáneamente.
Sin embargo, el almacenamiento de clave-valor presenta algunas limitaciones cuando se trata de realizar consultas complejas o trabajar con datos estructurados. En este modelo, no existe un lenguaje de consulta estructurado (como SQL) que permita realizar búsquedas sofisticadas, y las relaciones entre los datos no se gestionan de manera natural. Esto hace que las bases de datos de clave-valor no sean adecuadas para aplicaciones que requieren consultas complejas o análisis de datos, ya que solo permiten realizar búsquedas basadas en la clave. Por ejemplo, no se pueden realizar búsquedas sobre valores específicos dentro de un conjunto de datos sin tener la clave exacta.
Además, debido a su falta de estructura, el almacenamiento de clave-valor no es adecuado para aplicaciones que requieren mantener relaciones entre los datos o aplicar reglas de negocio complejas. Por ejemplo, en un sistema de gestión de inventarios, donde los productos deben estar relacionados con categorías, precios y cantidades, un modelo de clave-valor sería menos eficiente que un modelo de base de datos relacional o de documentos, donde las relaciones entre estos atributos pueden gestionarse de forma más natural.
A pesar de estas limitaciones, el almacenamiento de clave-valor es ideal en casos de uso de alto rendimiento donde la simplicidad y la velocidad son esenciales. Un ejemplo común es el uso de bases de datos de clave-valor como Redis o Amazon DynamoDB para la gestión de sesiones de usuario en aplicaciones web. En estos casos, cada sesión de usuario puede ser representada como un par de clave-valor, donde la clave es el identificador único del usuario y el valor es el conjunto de datos asociados a esa sesión (como preferencias, historial de navegación o credenciales de autenticación). Estas aplicaciones requieren una alta velocidad de acceso y no necesitan realizar consultas complejas, lo que hace que el almacenamiento de clave-valor sea una solución perfecta.
Amazon DynamoDB es un servicio totalmente administrado que utiliza el modelo de almacenamiento de clave-valor. DynamoDB es altamente escalable y ofrece un rendimiento de baja latencia, lo que lo hace ideal para aplicaciones móviles, juegos en línea, IoT y sistemas de gestión de sesiones. Su facilidad para escalar y su capacidad para manejar grandes volúmenes de datos con una latencia mínima lo convierten en una opción popular para muchas aplicaciones modernas.
En resumen, el almacenamiento de clave-valor es una opción ideal para aplicaciones que requieren alta velocidad de acceso a datos y donde la estructura de los datos es sencilla y no requiere relaciones complejas. Sin embargo, debido a su simplicidad, no es adecuado para aplicaciones que necesitan realizar consultas complejas o mantener relaciones entre los datos. Este modelo destaca especialmente en sistemas de caching, gestión de sesiones y aplicaciones que requieren una escalabilidad rápida y eficiente.
Conclusión
El mundo del almacenamiento de datos es vasto y diverso, y cada tipo de sistema tiene sus propias fortalezas y limitaciones. Desde las bases de datos relacionales hasta los modelos de clave-valor o documentos, cada solución se adapta mejor a diferentes necesidades y casos de uso. Los modelos de almacenamiento en filas y columnas ofrecen ventajas específicas para transacciones y análisis de datos, respectivamente, mientras que los sistemas de clave-valor y documentos proporcionan agilidad y escalabilidad para aplicaciones que manejan grandes volúmenes de datos no estructurados o transitorios.
El poliglotismo de persistencia es una estrategia clave que permite a las organizaciones aprovechar lo mejor de cada tecnología de almacenamiento. Al integrar diferentes tipos de bases de datos para manejar distintos aspectos de una aplicación, se logra una optimización tanto en rendimiento como en escalabilidad. Sin embargo, la implementación de este enfoque debe manejarse cuidadosamente para evitar la complejidad operativa y garantizar la coherencia de los datos entre los diferentes sistemas.
Al final, la elección de una estrategia de almacenamiento adecuada depende de las necesidades específicas de cada aplicación, el tipo de datos que se manejan, y la arquitectura de la solución en general. Con el crecimiento continuo de las tecnologías de bases de datos y la flexibilidad de plataformas como AWS, los equipos de desarrollo tienen ahora más opciones que nunca para construir sistemas de almacenamiento eficientes, escalables y capaces de adaptarse a los desafíos del futuro.

Deja un comentario